When LLMs Disagree: Testing Local Models on Contract Classification
February 2026
Quick Brief
- Experiment: evaluation of whether legal contract analysis can run entirely on a local laptop using open-source LLMs.
- Why it matters: many organizations are reluctant to send sensitive documents (contracts, financial records, internal agreements) to AI systems outside their organization.
- Key insight: the model itself is only a small part of the system. Most of the work happens in the surrounding pipeline, and ambiguous documents can still make different models disagree.
Context
Organizations are increasingly enthusiastic about using AI on their documents. They are somewhat less enthusiastic about sending those documents to someone else’s API.
Which raises a fairly practical architectural question: how far can document analysis go if everything stays local?
To explore this, I built a small prototype pipeline that processes uploaded PDFs and attempts to classify and extract information from legal contracts using locally hosted LLMs.
Experiment Setup
The experiment was deliberately simple: upload a document, decide whether it is a contract, and if so extract useful information from it.
Under the hood, the system is mostly a pipeline. The model itself only appears halfway through the process.
 Most of the steps have nothing to do with AI.
Most of the steps have nothing to do with AI.
The document passes through text extraction, normalization (stripping repeated headers, collapsing whitespace, marking page boundaries), and chunking before the model sees a single character. The first LLM call is step four of eight.
Three open-source models were evaluated:
All models ran locally using Ollama.
The hardware was intentionally modest: Apple MacBook Air (M3) with 16GB RAM. The goal was not peak performance but to evaluate whether local inference is practical for structured document workflows.
Test documents were chosen to represent both clear and ambiguous document categories.
Observations
A few patterns appeared fairly quickly during testing.
Performance
The models ran successfully on modest hardware. They were just not in a hurry.
Simple classification tasks required roughly 20-30 seconds. Full contract extraction on longer documents could take more than 13 minutes.
So while the pipeline works, it is not particularly fast.
In practice, runtimes like these would limit fully local pipelines to batch-style workflows rather than interactive applications.
Behavior on Clear vs Ambiguous Documents
The models behaved consistently when the classification task was unambiguous.
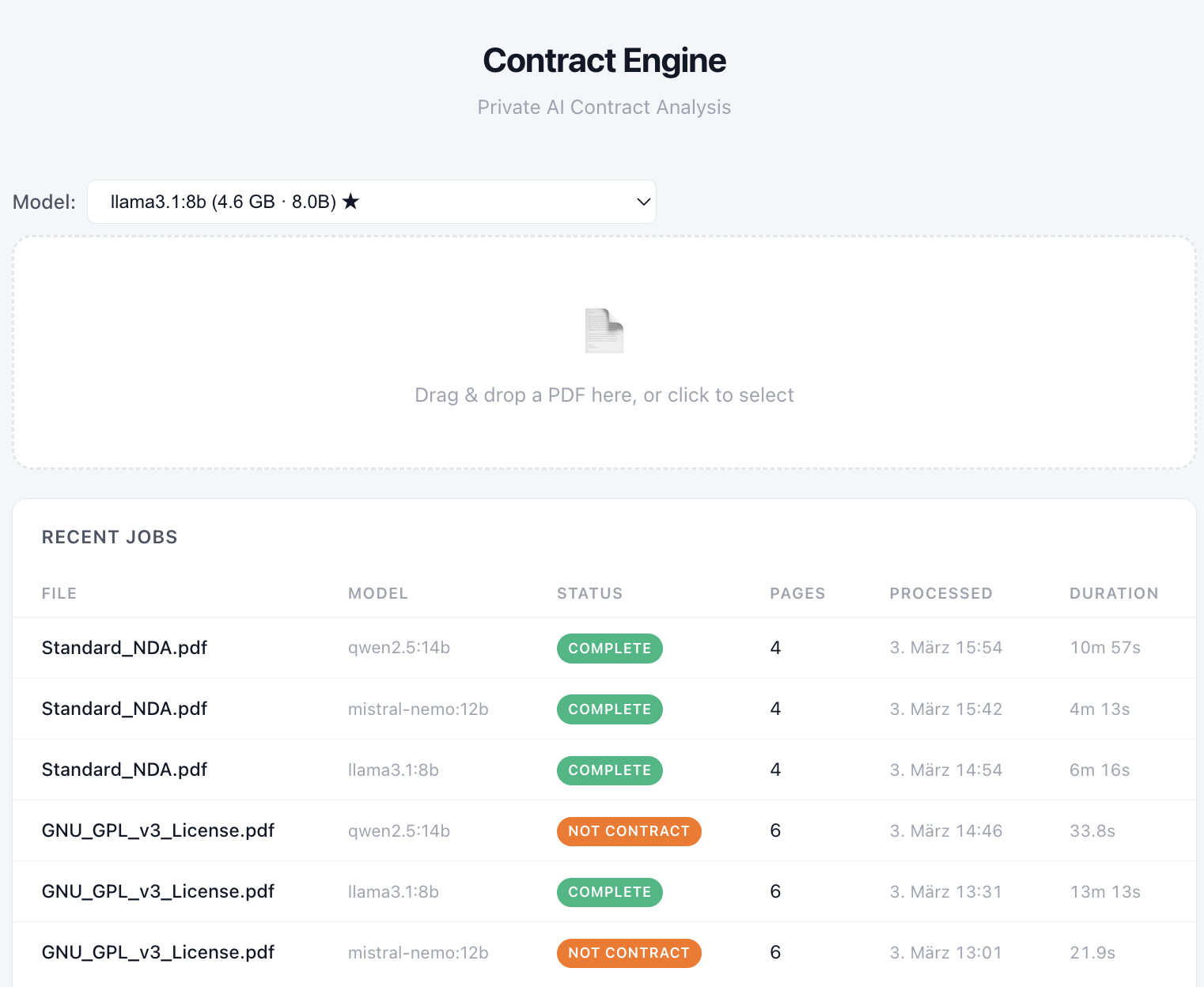
As a simple control test, a CV was uploaded first. All three models correctly identified that the document was not a contract and stopped processing.
A second test used a generic NDA without identifying names. Here again, the models agreed: all three classified the document as a contract and proceeded to extract participants and potential risk indicators.
So far, the models appeared to have a fairly clear idea of what a contract looks like.
 Apparently the problem “contract / not contract” is slightly harder than “hotdog / not hotdog”.
Apparently the problem “contract / not contract” is slightly harder than “hotdog / not hotdog”.
The divergence appeared once the document category became legally ambiguous. A GNU General Public License v3 was used as the next test document.
At this point the models behaved a bit like lawyers: they disagreed.
- Mistral classified the document as not a contract. Its reasoning: “The document is a GNU General Public License, which grants permissions and sets conditions for using, modifying, and distributing software.”
- Qwen reached the same conclusion and stopped further processing. Its reasoning: “The text is a license agreement, specifically the GNU General Public License version 3, which outlines permissions and conditions for software distribution but does not contain named parties or specific legal obligations typical of a contract.”
- Llama 3.1 reached the opposite conclusion. It classified the document as a contract and continued with full information extraction. Once it did, the system produced structured output: 33 clauses, 24 obligations, and 3 identified risks. Among the extracted risks were a termination trigger rated as high risk (“automatically terminate your rights under this License…”) and an unlimited liability clause.
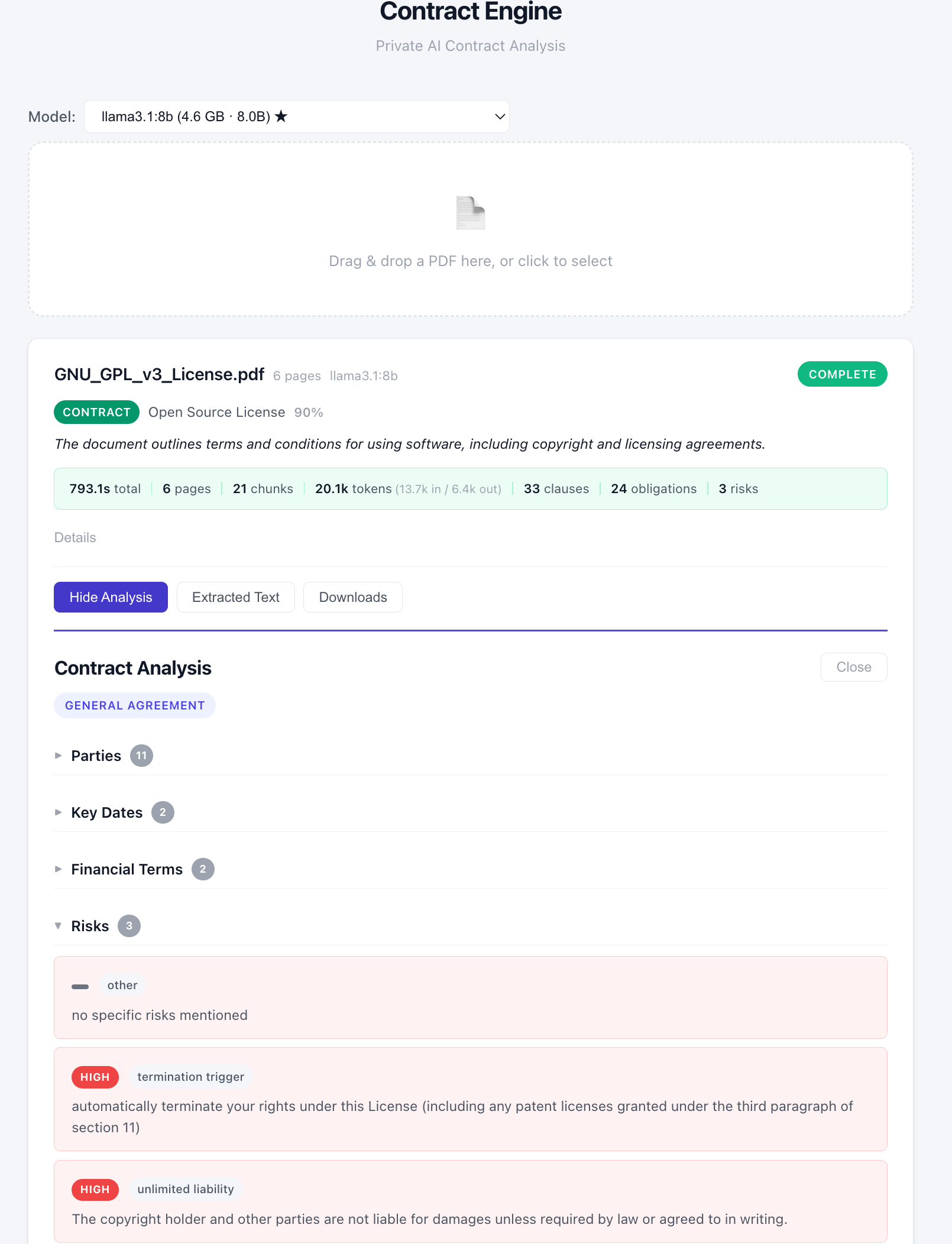 Once the model decides the document is a contract, the analysis proceeds with confidence.
Once the model decides the document is a contract, the analysis proceeds with confidence.
This suggests that model behavior remains relatively stable for clearly defined document types, but becomes less reliable once categories are legally or semantically ambiguous. Which, conveniently, remains a fairly common situation in law.
| Llama 3.1 (8B) | Mistral NeMo (12B) | Qwen 2.5 (14B) | |
|---|---|---|---|
| CV | ❌ | ❌ | ❌ |
| NDA | ✅ | ✅ | ✅ |
| GPL v3 | ✅ | ❌ | ❌ |
✅ contract ❌ not contract
Unanimous on the easy cases. A 2–1 split on the hard one.
So What?
Local inference works for privacy-sensitive preprocessing. Classification, detection, extraction. All fine. It is just not fast. Multi-minute runtimes mean batch workflows, not interactive applications. On current consumer hardware, this is a triage tool, not a real-time one.
The more interesting problem is the disagreement. When the task is unambiguous, the models converge. When it is not, they diverge. And they do so with full confidence. No model said “I’m not sure.” They each committed to a position and moved on. This is exactly the kind of behavior that makes local-only deployment risky for anything legally significant.
In practice, a production system would need to be hybrid: local models for triage, stronger models in a controlled environment for the hard cases. And when even the stronger models disagree, perhaps an actual lawyer.
Which raises the obvious next question: if you give the stronger models the same ambiguous document, do they agree? Or do they just disagree more eloquently?
Licensed CC BY 4.0. Quote it, excerpt it, build on it – credit the author and link back.