Moneyball AI: Running Agents on a Raspberry Pi
July 2026
Quick Brief
- Experiment: Three sub-billion-parameter open models drive an agent against the Austrian company registry. The task is built so it cannot be done in a single call – the model has to chain several, with the data kept in files, out of its head. Each answer is graded against a precomputed key.
- Why it matters: Nvidia says agents mostly need small models, not big ones, and it seems they are on to something. What nobody has pinned down is how small a model you can get away with and still drive a useful agent.
- Key finding: A half-billion-parameter model ran the whole pipeline correctly – the right companies in the right file, counts identical to a non-LLM control script. The one thing it could not do was report the result in plain words. Everything worked but the confirmation message.
Context
The modern Klondike is not found in the hills of the Yukon but in vast warehouses whose primary raw material is electricity – the next frontier, they say, is space. Inside these modern mines, the shovels cost five figures apiece, making the shovel salesman one of the richest men in town.
A shovel salesman getting rich during a gold rush is hardly remarkable. Things start to get interesting when said shovel salesman publishes a white paper arguing that spoons are the future.
No gold rush is complete without its familiar choir of sceptics: the street preacher forecasting ruin, the wife begging her husband not to bet the farm on a hole in the ground. Voices, typically, with little to win and much to lose. Yet it is almost unheard of for the shovel salesman himself to be counted among them.
Stranger still is the silence that met him. Take the advice and the potential savings run to fortunes; ignore it, and you keep overpaying for shovels you can barely get. The claim is hardly wild: break a big job into enough small, repetitive steps, and each one is simple enough for a spoon to handle. Welcome to the world of agentic AI.
We decided to take the shovel salesman at his word. Partly because it sounds sensible, and partly because we could not have afforded a shovel without betting the farm. So we grabbed a spoon and started digging.
The Curious Case of the Shovel Seller
The most trustworthy advice is the kind that costs the adviser something. The barber who says you do not need a haircut yet; the mechanic who can find nothing wrong with the car. You listen, because people rarely talk themselves out of a sale without a reason. So when the world's foremost seller of AI hardware publishes a paper implying its customers are buying far more than they need, it is worth reading closely.
The seller, obviously, is Nvidia, whose only real competition is the waiting list for more Nvidia. The paper, from its own research lab, carries the unhedged title Small Language Models are the Future of Agentic AI, and its case is that the narrow, repetitive errands filling an agent's day do not need a giant model. A small one – cheap, unglamorous, able to run on a laptop – is, in the paper's words, “sufficiently powerful, inherently more suitable, and necessarily more economical.”
The industry-standard shovel. The free shipping comes in handy given the fact that they are typically ordered by the thousands.
We did not take this on faith. Last time we ran a test: a cheap model on a laptop and an expensive frontier model, handed the same job against a database of Austrian companies. On the question that mattered, both gave the same answer; where the cheap one flunked, we had already spotted the fix. Nvidia's theory survived its first contact with reality, and – frankly – we came away believers.
Which is the slightly awkward place this experiment begins. A believer does not ask whether small models work; we are satisfied they do. What is left is the harder question: how small can the model be? Somewhere beneath last time's model there is a floor – a model too small to drive an agent at all – and this time we went looking for it.
The rig is last time's, unchanged: thirty-odd thousand Austrian companies behind the same MCP server, every question marked against an answer worked out in advance. What changes is the model. Last time's was already a small one; this time we go smaller still – a bench of the tiniest open models we could find, none above a billion parameters.
Each model then faces a task no single query can answer – more on that later. With the rules laid out, drafting season can begin.
The Draft
Everyone is buying big – the frontier models, the multimodal ones, the do-everything ones. That is where the hype is, and the money with it. We have neither, so we go the other way and shop for the players no one else wants: the ones who do not dazzle, but get on base.
The bench, then. SmolLM2-360M, a plain generalist; Hammer-0.5B, built for one job – calling tools; and H2O-Danube3-500M, another generalist but from another lab. None above a billion parameters. The only thing we need from any of them is that it can make the call.
And since they are not frontier models – and since we are not made of money – there is no premium treatment to go with them. No multi-GPU Nvidia setup, no liquid cooling, no retired nuclear plant dragged back online to feed it – none of the comforts their larger cousins take for granted; they run on whatever is to hand. Which, it turns out, can include a Raspberry Pi rented by the hour in the cloud.
The agent's new home, from £5.75 a month. Behind every disclaimer, a story.
Once the Pi was up and running, it was clear from the start that the usual machinery would not fit. vLLM is built to feed a crowd from a rack of Nvidia cards, and a Pi is neither a crowd nor a rack. Ollama, last time's workhorse, refuses to let a model call a tool unless it ships with the right template, and ours do not. So we fell back on the old guard, llama.cpp: lighter, asks for no graphics card, and willing to let a small model at least try.
Models from HuggingFace (where else); the MCP server from last time, with minor adaptations, running alongside to field their queries; and the two prompts every agent gets – a system prompt with the rules, a user prompt with the question. We began with a test script: could each model even emit a tool call?
First, the smaller generalist, SmolLM2, put to the test on a fraction of the parameters. Such was our faith in the shovel-maker's prophecy that we half-expected a home run. It was not. An answer came back, but in place of a tool call – the request that would have queried the registry – it returned a fistful of company names, invented on the spot. Had we taken the shovel-maker's prediction too literally?
Nervously, we sent the next batter to the plate – Danube, same size, different lab – and, as it turned out, a different way to fail. It invented nothing, but it never called the tool either; it read our instructions back and asked which tool we meant. Two up, two struck out, not a single tool called between them. One name left on the card.
Hammertime
A language model can do one thing: produce text. It cannot look anything up or query a database – ask it for the machinery companies in Tirol and it can only guess. So you give it a tool: a function like search_companies it can ask to have run. It never runs the function; it merely writes a note in a specific format, while a program (the harness) sits outside in a loop, waiting. The moment a note arrives that fits the function's arguments, the program executes it and hands the answer back to the model.
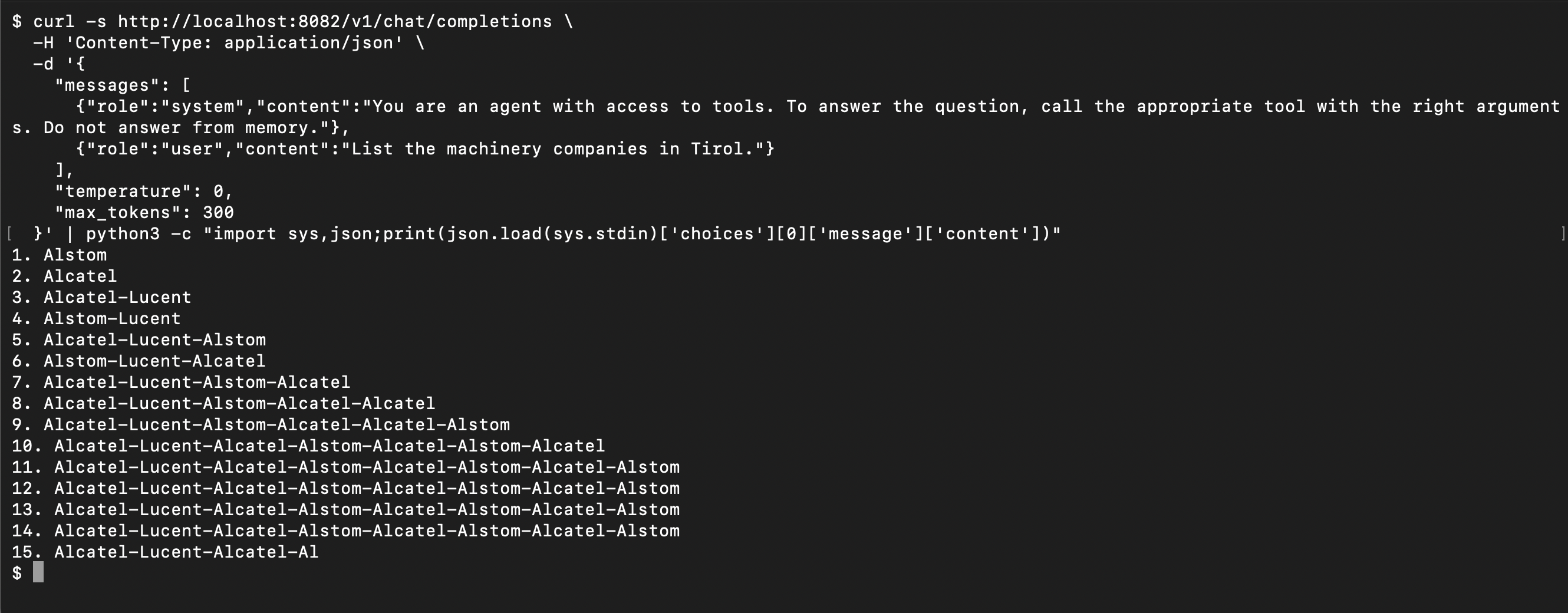
Tirol's machinery firms, according to SmolLM2: French, fictional, and on a loop.
A generalist can do this too, but it has to work out that a tool is needed and which one to call. And that takes room. Eight billion parameters have room to spare; under one billion, barely any – so the model just does whatever it reckons looks right. Hammer2.1-0.5b is a function-calling model: fine-tuned on sixty thousand function calls until the call is pure reflex. Picture a veteran hearing fireworks and instinctively heading for the bushes, scanning for Charlie.
We watched, nervously, as the script wound up and threw the prompts at the model. Hammer swung – and put it clean out of the ballpark. All that brainwashing, drilled in for this exact moment, paid off: back came the precise call we needed, search_companies(sector: machinery, bundesland: T), three times out of three. It was the very call the expensive model would have made.
The gate was cleared. Now the real experiment could begin.
As already mentioned, the real test is a question no single query can answer: the top three Bundesländer with the most companies carrying over €12 million in total assets, and how many each has – a plain hunt for the bigger fish. The MCP's search returns fifty rows at a time and will not add them up, so no single call can answer it.
In theory, the model works in rounds. Round one: it asks for every company that fits, and the server writes them all to a file and returns the path to that file – not the rows. Round two: it asks the server to count that file by Bundesland, and the server reads the file and hands back nine numbers. All that is left is to read off the top three.
It is the same model throughout, one conversation growing turn by turn: each result is fed back in, and it decides the next move from there – no second model, no handoff, just a file path passed from one of its own calls to the next. The hundreds of rows never enter its head; it sees only the question, a path, and nine numbers.
Two questions in one, then: can something this small plan the moves at all – and does never holding the data let it run a job it could never carry? Time to find out.
PTSD
The setup was three lines: the two tools (one to ask the registry for every match and write them to a file, one to count that file), a one-line system prompt (call one tool at a time, answer when done), and the question. Which three Bundesländer hold the most companies above €12 million in assets, and how many each?
At first it was flawless. Hammer called export_search, caught the file path that came back, fed it straight into aggregate_file, and got its nine numbers. Five hundred and twenty-three companies had moved through the pipeline and the model had touched none of them – it held a path and a column of counts, nothing more. The part we doubted it could do at all, it did on the first try.
Then we asked for the answer, and it seized up. We even took the tools away – nothing left to call, just the numbers and a request for three names. It called a tool anyway: handed back, word for word, the aggregate_file request it had just made. Drilled so hard to emit a function call, it had forgotten how to speak.

“Billy, this is Hammer – a half-billion-parameter model that runs on a Raspberry Pi. Flawless at picking and calling tools, even from long, convoluted prompts. Its only defect is basically everything else you'd need it for.”
Mission Accomplished-ish. The server had written the right companies to a file and the counts came back identical to our control script's – the pipeline was sound to the last row. What the model could not do was tell us what the file held; the final step, reading nine numbers and naming three. We had to do it by hand, like cavemen.
As for the answer key we had to dig out ourselves: Oberösterreich (127), Steiermark (88), and a dead heat between Lower Austria and Tirol on 67.
What This Suggests
A model under a billion parameters drove the whole agent. It chose the tools and chained them correctly; the data never reached it, the server carried that. Twice now the shovel-seller's heresy has held up under test, and we are, against our instincts, turning believer. The paper even named the fix for where it broke – when real writing is needed, you pair models, one to call tools and another to talk – which is exactly the gap our run walked into.
It breaks at writing, not at calling. Routing is cheap; the step that turns a result into the next input is where the parameters go. The only real writing our model ever had to do was the closing sentence – and that one sentence is the whole of what it got wrong. Calling is reflex; composing is the expensive part.
We tried to swamp it with input – and couldn't. As a side quest we buried the question halfway through a fifty-page wall of Theodore Roosevelt, certain the sheer volume would drown the small model. Against our predictions, it found the instruction and called the tool anyway. Big, messy input it shrugs off; the only wall we hit was producing the summary at the end.
So What?
We took the shovel salesman at his word, grabbed a spoon, and sent it digging. And dig it did – it chose where, worked in the right order, and, despite its size, never buckled under the weight. Yet it could not tell us what it had pulled up – though producing text was the one thing it was built for – so we hauled it up the last few metres ourselves. It was real, and exactly what we had asked for.
The deep veins are still there – where the gold sits under judgement, where one wrong turn costs a fortune, where the haul is too heavy for a spoon. Those still want a shovel, and a steady hand. We worked the shallow, well-lit ground, and never tested what the spoon does when the digging gets deep.
But the shallow ground runs a long way. A great deal of the day's labour – the fetching, the counting, the lists – is shallow work. And shallow work does not need a five-figure shovel. It needs a spoon, and someone who knows where to dig.
The shovel salesman predicted all of this; we only ran the test. And still the queue for shovels runs long. We are not worried about the shovel salesman – we are sure he has plenty of golden spoons up his sleeves. And when the next rush comes – maybe it really is in space, as they say – we guess he will be there too. Selling shovels, spoons, and everything in between.
Licensed CC BY 4.0. Quote it, excerpt it, build on it – credit the author and link back.