Better Call Saul(LM): Do Bigger Models Actually Agree on Ambiguous Documents?
March 2026
Quick Brief
- Experiment: Six open-source LLMs classified four legally ambiguous documents. Three small models ran locally on a MacBook Air; three larger models ran remotely on an Nvidia H100 in a European data centre. One of the six was a legal-domain specialist.
- Why it matters: If an LLM is being used as a classification gate in a document pipeline, the important question is not just whether it works on easy cases, but how stable it is on borderline ones.
- Key finding: Temperature 0.1 is often treated as near-deterministic. That didn’t stop one model from classifying the same document as both CONTRACT and NOT CONTRACT on successive runs. Scaling up shifted the bias without resolving it. The one legal specialist in the set produced the most structurally precise reasoning.
Context
A previous experiment asked a practical question: can contract classification run entirely on a local laptop using open-source models? On straightforward documents, the answer was broadly yes. On the harder ones, the models split.
That raised the more interesting follow-up. If the problem is ambiguity, does scaling up push models toward consensus? Or do they just arrive at different forms of certainty, for more money?
The short answer is, that they just disagree more eloquently.
The longer answer involves a legal-specialist LLM, an Nvidia H100 in Warsaw, and the mildly awkward discovery that a MacBook Air can outpace a data center GPU under the right (i.e., wrong) conditions.
The Setup
The broader pipeline processes uploaded PDFs through a series of steps: text extraction, normalisation, whitespace cleanup, classification, chunking, analysis, and structured output. The LLM only appears at the classification stage. It sees the beginning of the document and is asked a narrow question: is this a contract or not?
All runs used temperature 0.1. In theory that should make the output close to deterministic: mostly greedy, with a small amount of sampling noise left in the system.
One caveat should be stated upfront. The prompt includes the phrase “contract, legal agreement, or terms of service.” That wording should nudge models toward classifying a Terms of Service document as a contract. Some models followed the hint. Others ignored it entirely.
The following four documents were chosen because they sit in the grey zone between “clearly a contract” and “clearly not”:
| Document | Why it is ambiguous |
|---|---|
| GNU GPL v3 | A licence with obligations, conditions, and restrictions, but no named parties or signatures. |
| Creative Commons BY-SA 4.0 | Rights and conditions are present, but in a permissive licensing form rather than a conventional bilateral agreement. |
| Sample Terms of Service | The classification prompt literally mentions “terms of service.” Does the model take the bait? |
| Sample MoU | Not always legally binding in the strict sense, but structurally very close to a contract. |
For the record: the author does not have a law degree and makes no claim to understand what actually constitutes a contract. The models, as it turned out, didn’t either.
Round One: The Local Court
The first three models were the same small open-source models used in the earlier laptop experiment, all running locally via Ollama on an Apple MacBook Air (M3, 16 GB RAM):
Before testing the new documents, there was an obvious sanity check. In the previous experiment, Llama3.1:8B had classified the GPL v3 as a contract. Same model, same document, same prompt, same machine, same temperature: that result should at least be reproducible.
It was not.
On the first rerun, Llama classified the GPL as NOT CONTRACT, with 90% confidence. Its reasoning this time was that the document “grants permissions rather than establishing a contractual relationship.”
The experiment could not even be reproduced before it had properly started!
So the run was repeated.
On the second attempt, the same model classified the same document as CONTRACT, again with 90% confidence, and went on to produce a full contract analysis. This time the reasoning leaned on the existence of “terms, conditions, and obligations.”
Both readings are defensible. That is precisely the issue.
Temperature 0.1 is supposed to reduce randomness to a negligible level. But on a document sitting near the decision boundary, even a very small amount of sampling noise appears capable of flipping the verdict.
That finding matters more than it first seems. If a classification gate can switch sides on the same input without any substantive change in setup, the relevant property is not “accuracy.” It is stability.
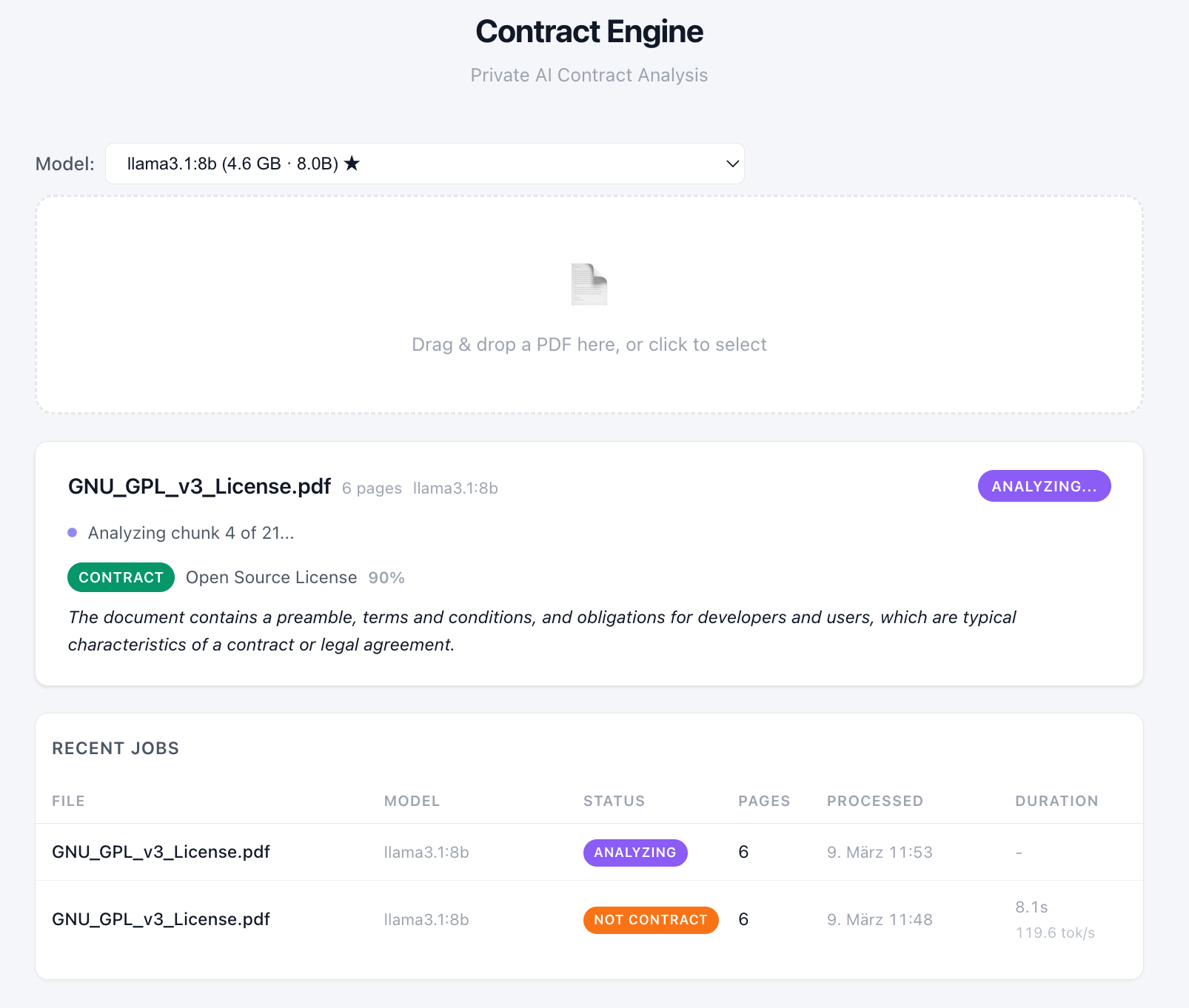 A useful feature of near-determinism is that it occasionally is not. On an earlier run, the same document (GPL) came back NOT CONTRACT. Minutes later, with the same setup, Llama decided otherwise.
A useful feature of near-determinism is that it occasionally is not. On an earlier run, the same document (GPL) came back NOT CONTRACT. Minutes later, with the same setup, Llama decided otherwise.
The remaining local runs were more stable. Mistral and Qwen both confirmed their earlier GPL classifications without visible drama. With that settled, all three models were given the remaining three ambiguous documents.
| Document | Llama 8B | Mistral 12B | Qwen 14B |
|---|---|---|---|
| GPL v3 | 🤷♂️ | ❌ | ❌ |
| CC BY-SA 4.0 | ❌ | ❌ | ❌ |
| Terms of Service | ❌ | ❌ | ✅ |
| MoU | ✅ | ❌ | ✅ |
✅ contract ❌ not contract
The GPL v3 was already tested in the previous experiment. Llama had classified it as a contract then. This time, it simply switched sides.
Across the full set, three observations stood out.
- First, Mistral was the hanging judge. It rejected all four documents. Its reasoning was consistently structural: no named parties, no signatures, no traditional deal.
- Second, Qwen was the most prompt-sensitive. The prompt mentioned “terms of service”, and Qwen appears to have taken that as relevant guidance. The other two models ignored it and did their own structural assessment.
- Third, confidence was useless. Every model reported 90–100% confidence, including on the cases where they disagreed with each other and the case where Llama disagreed with itself. On ambiguous legal documents, those confidence scores are better read as style than signal.
So the small models did not converge. On the easy cases they could be useful; on the ambiguous ones they exposed the boundary problem rather neatly.
At which point the obvious next step presented itself. If the lower court is divided, appeal.
Round Two: The Remote Models
A proper appeal needs proper hardware. The compute runs on Scaleway, a European cloud provider, which in the current geopolitical climate might be reassuring to some. Scaleway offers GPU instances in Paris and Warsaw. Paris was fully booked, so the court convened in Warsaw. The cost of this appeal: €2.73 per hour, billed per minute.
Once the hardware was running, vLLM was installed as the inference server.
 AMD EPYC, 240 GB system memory, Nvidia H100 PCIe with 80 GB VRAM. The bench is ready.
AMD EPYC, 240 GB system memory, Nvidia H100 PCIe with 80 GB VRAM. The bench is ready.
Three larger models were downloaded from Hugging Face and took the stand. Same documents. Same prompt. Same temperature:
- Llama-3.1:70B – the bigger sibling of the 8B that couldn’t agree with itself
- Qwen2.5:72B – the bigger sibling of the 14B that was the lone dissenter on Terms of Service
- SaulLM:54B – a Mistral derivative fine-tuned on US and European legal texts, court rulings, and legislative documents
This created two useful comparisons at once: scale within a model family (Llama 8B vs 70B, Qwen 14B vs 72B) and generalist versus specialist (Mistral-family generalist vs SaulLM, its legal derivative).
SaulLM was the most interesting model in the set, because it tested a different thesis entirely. Not “does bigger help?” but “does domain training help?”
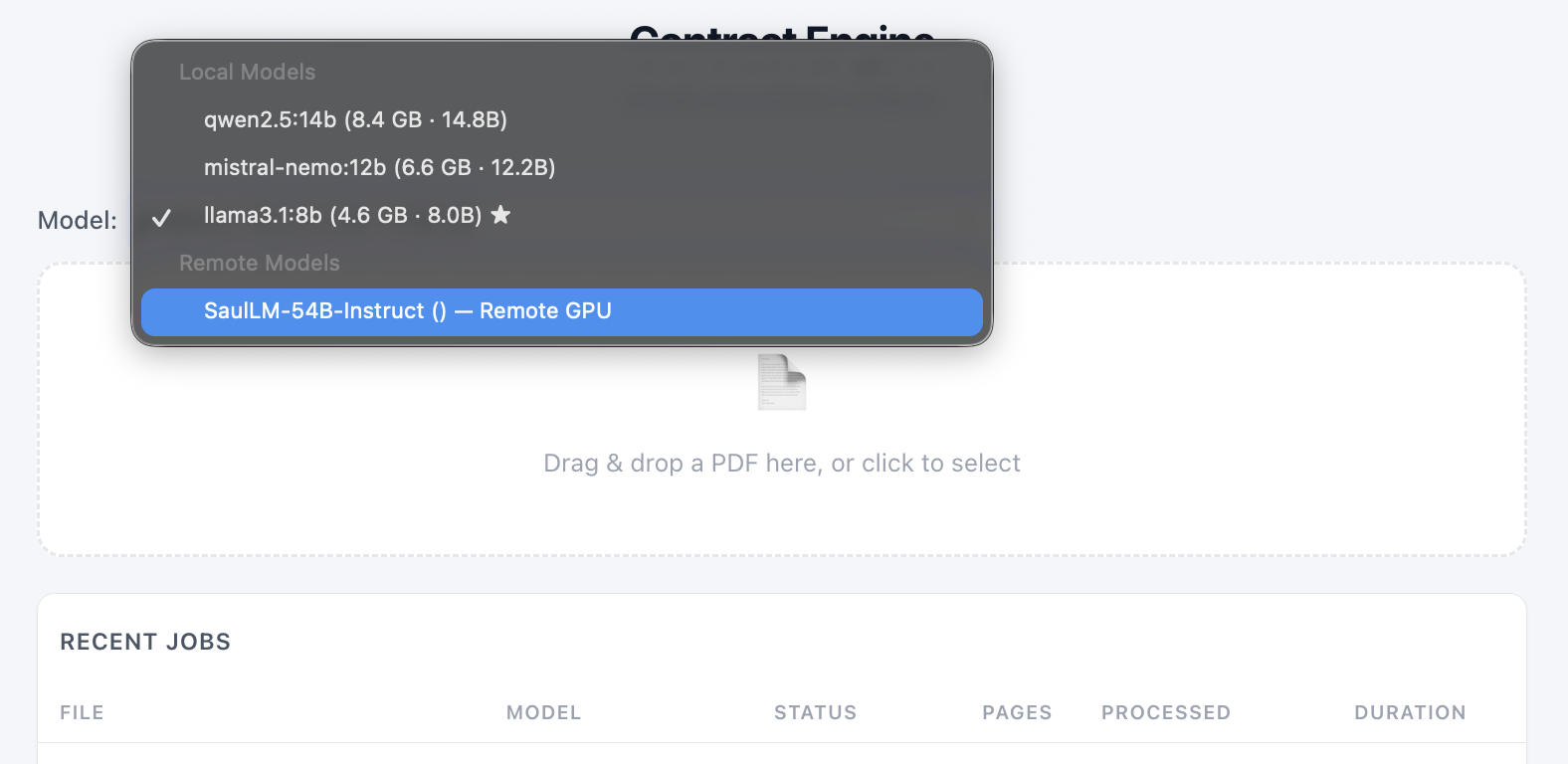
So the first model to take the bench was the specialist: SaulLM:54B, a legal-domain LLM fine-tuned on court rulings, legislative documents, and legal texts from both sides of the Atlantic. The kind of model you bring in when the generalists can’t agree. (A larger 141-billion parameter version also exists, but it didn’t fit on the hardware. Even the H100’s 80 GB of VRAM has limits.)
 The honourable chief justice. SaulLM 54B, presiding.
The honourable chief justice. SaulLM 54B, presiding.
SaulLM looked at the four documents and delivered its opinion with the quiet confidence of a model that has read a lot of case law. And it was fast. 820 to 1,400 tokens per second on the three documents it rejected – under two seconds to a verdict. This is what happens when an H100 meets a model that doesn’t waste compute.
It classified three of the four documents as NOT CONTRACT, with only the MoU receiving a clear CONTRACT verdict. That already put it closer to a defensible legal-structural reading than the larger generalists.
But in the interest of judicial transparency, a potential conflict of interest must be disclosed.
SaulLM is built on Mixtral. Same model family as Mistral NeMo, the hanging judge from the local court who voted NO on every single document. The legal specialist and the generalist share the same DNA, but their verdicts do not fully reflect it: SaulLM matched Mistral’s vote on three out of four documents.
But not on the fourth.
Mistral 12B rejected the MoU. SaulLM accepted it. The specialist appears to have recognised what the smaller generalist did not: named parties, explicit obligations, and contractual structure matter, even if the document sits in a legally fuzzier category. That is a more useful kind of improvement than simply saying “yes” more often.
The Larger Generalists: Oyez! Oyez! Oyez!
The remaining two remote models were the larger siblings of the local ones, as we wanted to test whether verdicts run along family lines, the way ideology runs along party lines on the US Supreme Court.
Llama3.1:70B classified all four documents as CONTRACT. That is not a slight shift from its 8B counterpart. It is a complete reversal in disposition. The smaller Llama was cautious and inconsistent. The larger one was permissive and absolute. Scale did not stabilise the boundary; it moved it.
Qwen2.5:72B classified three of four as contract. It agreed with its 14B sibling on GPL v3, Terms of Service, and the MoU, but flipped on CC BY-SA 4.0, deciding that the Creative Commons licence counted as a legal agreement.
Again, the larger version was not obviously more precise. It was simply more willing to classify borderline documents as contracts.
With all twenty-four classifications complete, the combined picture looked like this:
| Local | Remote | |||||
|---|---|---|---|---|---|---|
| Document | Llama 8B | Mistral 12B | Qwen 14B | Llama 70B | SaulLM 54B | Qwen 72B |
| GPL v3 | 🤷♂️ | ❌ | ❌ | ✅ | ❌ | ❌ |
| CC BY-SA 4.0 | ❌ | ❌ | ❌ | ✅ | ❌ | ✅ |
| ToS | ❌ | ❌ | ✅ | ✅ | ❌ | ✅ |
| MoU | ✅ | ❌ | ✅ | ✅ | ✅ | ✅ |
✅ contract ❌ not contract
Meta Mistral Alibaba
The verdict of what actually constitutes a contract is in. It is… confusing.
No stable coalition emerged. The only near-consensus document was the MoU, which five of the six models classified as a contract. Everything else produced splits.
Some disappointing news from the capital expenditure front
There was also an unplanned infrastructure lesson.
On the MoU – which all three remote models classified as CONTRACT, triggering a full contract analysis rather than a short rejection – Qwen2.5:72B on the H100 was slower than Qwen2.5:14B on the MacBook Air. The H100 managed 9.7 tokens/sec. The MacBook managed 16.4. For comparison, the honourable SaulLM on the same H100 and the same document managed 300 tokens/sec.
This was not a referendum on Nvidia hardware. It was a software stack problem: a quantisation kernel incompatibility prevented the GPU run from benefiting properly from the hardware underneath it.
Still, the optics were good in the wrong sort of way. The expensive machine lost a sprint to a laptop on a kitchen table.
That is worth mentioning because it is exactly the sort of thing benchmark logic tends to omit. Infrastructure choices, runtime support, and model-serving details can matter as much as the model itself.
What this suggests
A few conclusions seem reasonably safe.
Borderline classification is not a one-model problem. If the input documents are genuinely ambiguous, a single model verdict is a fragile thing to build a workflow on. Even at low temperature, the classification boundary can wobble.
Confidence scores are not enough. The models were consistently confident, including when they contradicted one another and when one contradicted itself. Confidence here does not measure correctness. It mostly measures rhetorical commitment.
Bigger is not the same as better. The larger models did not converge on a more reliable answer. In both the Llama and Qwen families, scaling up mostly made the models more permissive. That may or may not be desirable, but it should not be confused with improved judgement.
Specialisation mattered more than scale. SaulLM was not the largest model in the experiment, but it produced the most plausible pattern of decisions. That suggests that for domain-specific classification, training data and task fit may matter more than sheer parameter count.
Limits of the experiment
A few caveats are worth making explicit.
This was a small exploratory test, not a benchmark. The sample size is tiny: four documents, six models, one prompt family. The prompt itself likely biased at least one document category. And the repeated-run instability was observed most clearly on one model and one document, not exhaustively measured across the entire matrix.
So the claim here is not that larger models are “worse,” nor that SaulLM is “right.” The claim is narrower and more useful: on ambiguous classification tasks, scale did not reliably buy stability, and domain specialisation looked more promising than raw size.
So What?
This experiment was never about finding the “right” answer. The GPL v3 is genuinely ambiguous. Reasonable lawyers disagree about whether open-source licenses are contracts (or so the author is told, being neither a lawyer nor anything remotely adjacent to one). Reasonable models do the same.
This is not really a story about contracts. It is a story about classification gates.
In production pipelines, those gates are often treated as simple. They are not simple. On easy documents, many models will look competent. On ambiguous ones, the disagreement is the signal.
That leads to a fairly unglamorous conclusion. A robust system probably needs some combination of:
- multiple models
- a disagreement or escalation path
- and a human in the loop for the cases that sit near the boundary
That is not a failure of the model. It is a recognition that the category itself is fuzzy.
When they disagree, that is not a failure. That is information. The mistake is building a system that pretends ambiguity doesn’t exist.
Licensed CC BY 4.0. Quote it, excerpt it, build on it – credit the author and link back.