Pimp My LM: A Fine-Tuning Tale of Bling and Basic
April 2026
Quick Brief
- Experiment: Three language models were fine-tuned on 64,000 EU regulations to classify legislation into 21 thematic domains. Two BERT-based models (110 million parameters each) ran on a free GPU. One Llama 8B ran on eight Nvidia H100s.
- Why it matters: In previous experiments, classical methods topped out at 0.80 whereas zero-shot LLMs barely cleared 0.56. Showing the model labelled examples – fine-tuning – is the obvious next step. The question is whether spending more buys anything.
- Key finding: All three models scored essentially the same – the best results in the series so far. The difference was the bill: less than €10 for the two small ones – that was the minimum purchase, most credits unused – and €83 for the large one. An order of magnitude more expensive for the same result.
Context
Give a model a task and it will guess. Give it examples and it will learn.
In previous experiments, we tried both. Four language models on high-end GPUs classified EU regulations into thematic domains without a single example – they scored around 0.50. Then a word counter on a MacBook Air, trained on 64,000 labelled regulations, scored 0.80 in five minutes and outperformed them all.
Which left one move on the board that has not been tried yet: give the language models the examples too. Show it the labelled regulations and let it learn the patterns. In the trade, this ancient technique is called fine-tuning – the principle behind every spam filter, but with considerably more compute.
A small model can be fine-tuned for free, a large one requires hardware that bills by the hour. The experiment would run the full range – free, cheap, and not cheap – and either the escalation would justify itself or it would not.
But first, a detour. It turns out the European Parliament has not only been writing regulations. It has also been building AI models to classify them. A discovery that felt a bit like being Scott arriving at the South Pole only to find a Norwegian flag already planted – except the flag was a HuggingFace repository, and the Norwegian was the European Parliament.
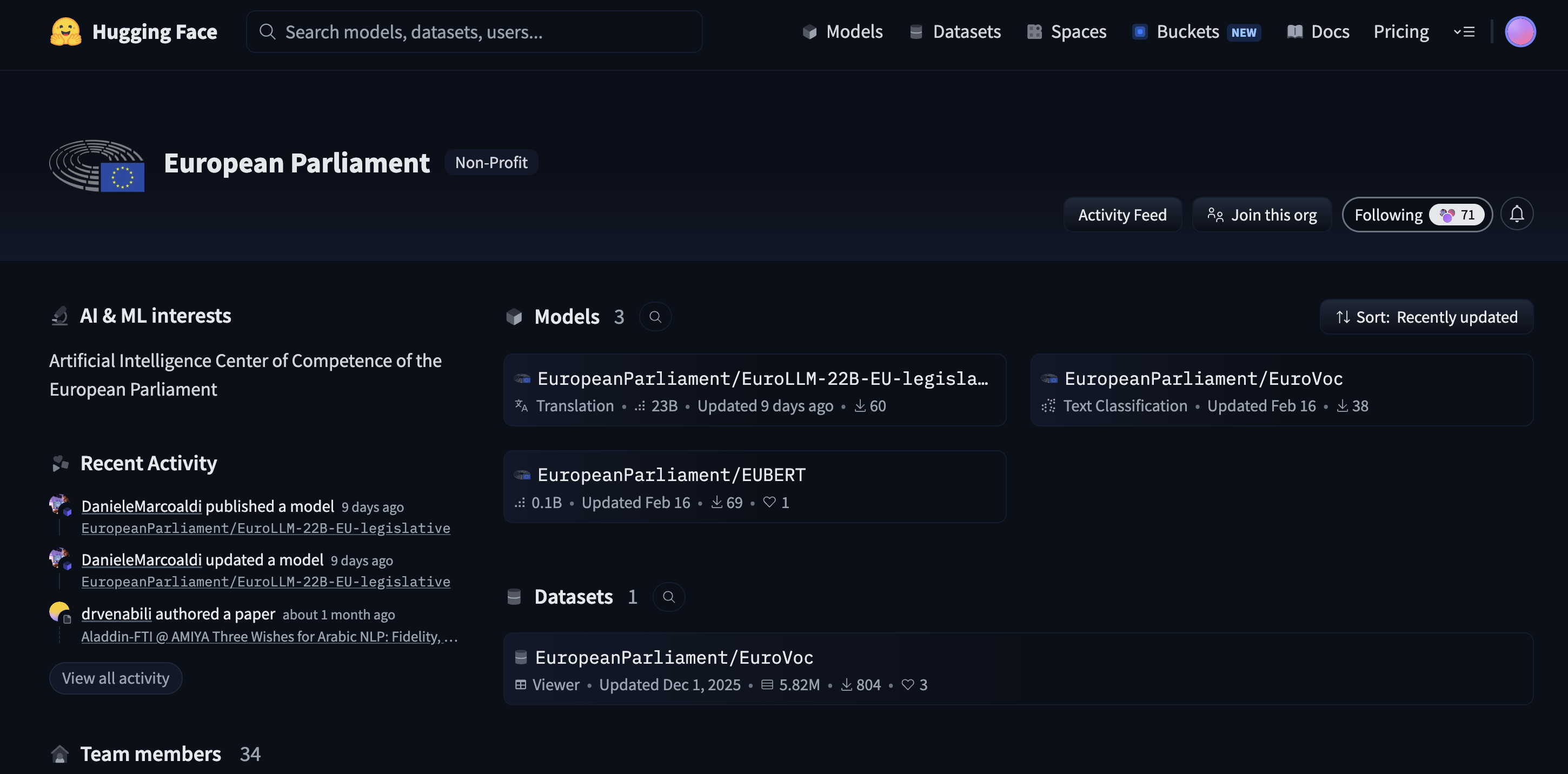
37 Downloads
HuggingFace is where machine learning models go to be proudly published, occasionally downloaded, quietly ignored, and inevitably forgotten. The European Parliament’s account fits this arc almost perfectly: three models and one dataset, with download counters in the double digits – a language model at 69 downloads, a classifier at 37, a translation model at 60. All as of April 2026. Not exactly trending.
 “Great God! This is an awful place and terrible enough for us to have laboured to it without the reward of priority.” – Robert Falcon Scott
“Great God! This is an awful place and terrible enough for us to have laboured to it without the reward of priority.” – Robert Falcon Scott
The language model is called EUBERT – same architecture as BERT, Google’s 2018 model, but trained from scratch on EU texts instead of Wikipedia and novels. 110 million parameters. Not a classifier in itself, but the foundation for one.
The classifier – named EuroVoc – takes that foundation and adds a classification layer on top, fine-tuned to assign thematic domains to EU legislation. The exact task this series has been trying to solve. Already done, already published, by the institution responsible for the taxonomy itself. Was the entire mission in vain?
The download counter was pushed to 38, and the investigation began. The classifier was downloaded, the environment set up, the dependencies installed.
Run. Nothing.
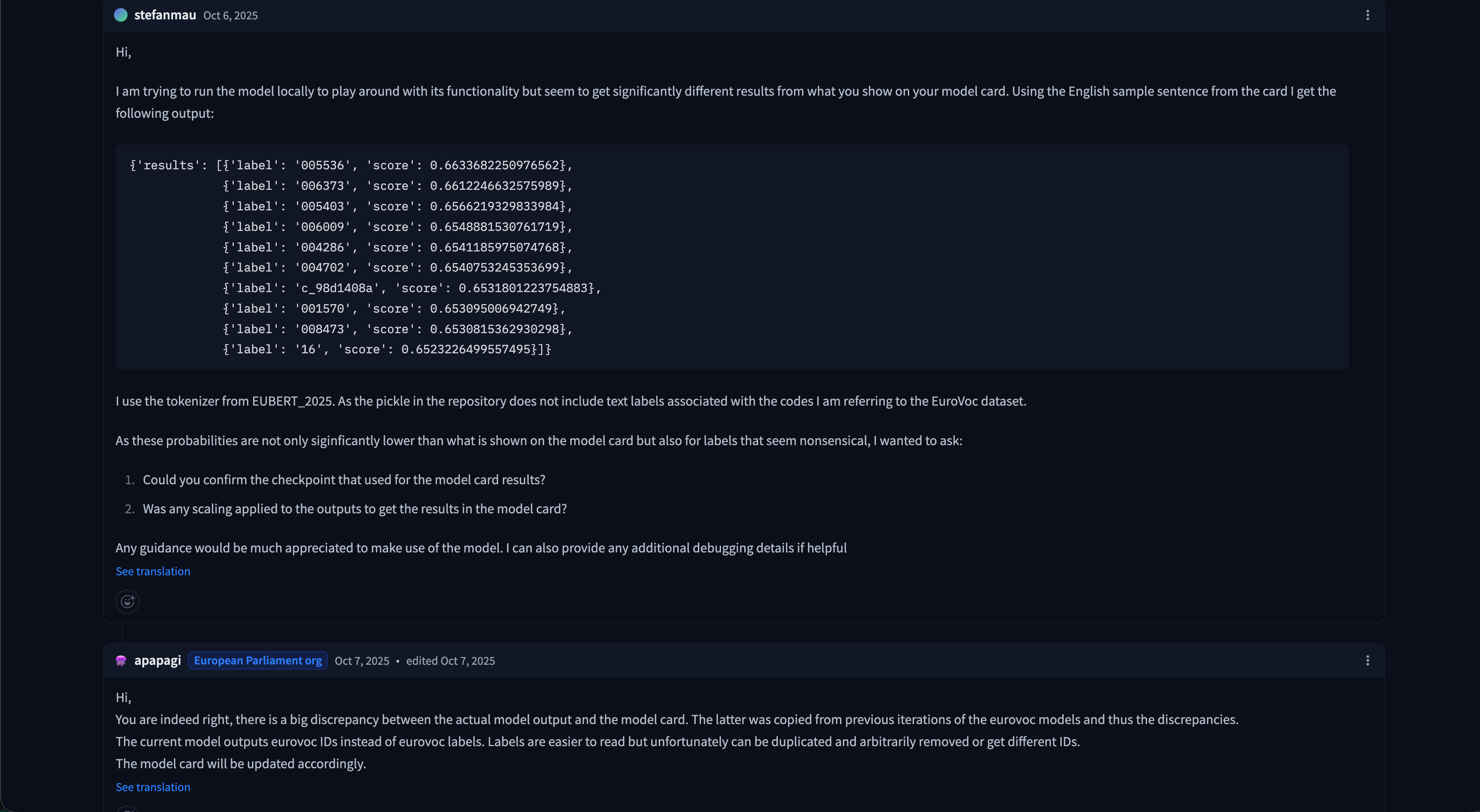
The model loaded without protest, accepted a regulation as input, and returned two labels: “LABEL_0” and “LABEL_1.” Not “trade.” Not “agriculture.” Not any of the 7,000 EuroVoc categories it was supposedly trained on. Two meaningless placeholders and a confidence score – the machine learning equivalent of a shrug.
Surely the mistake was on our end. This is the institutional model published by the European Parliament itself. Presumably reviewed, tested, and approved by the appropriate number of committees and sub-committees. After all, according to the model card, this was the official classifier “used in a production environment.” So the configuration was checked, the code was checked, and it was run once more.
Same result. Frustration set in. Then suspicion. It was decided to actually read the warnings.
The short version: the model ships with parts that do not fit together – the configuration declares a RoBERTa architecture while the weights inside are from a BERT model. Every trained parameter is silently discarded on load and replaced with random numbers. It is not a configuration problem or an installation error. The official published artefact is simply broken.
Further digging led to the comment section of said repository – where, despite only 37 downloads, someone had found the time to report that the model’s outputs bore no resemblance to what the documentation promised. In 2024. The Parliament responded, acknowledged the discrepancy, and then… did nothing. No fix, no update, no follow-up. The model “used in a production environment” does not, in fact, work as advertised.
 The community noticed. The Parliament noticed too, and decided to move on.
The community noticed. The Parliament noticed too, and decided to move on.
We were download number 38, and we were left with nothing that worked. The defeated spirit of Scott, arriving second to a broken flag, gave way to something closer to Amundsen – who, when he found no path, made one. The mission was back on.
The obvious next step: redo the fine-tuning from scratch, properly this time. Take EUBERT – the Parliament’s own foundation – and build a classifier that actually works. Cost it what it may, as long as the costs are not too high.
And why stop at one? For good measure, a second candidate: bert-base, Google’s original 2018 BERT. Trained on Wikipedia and novels, has never seen a regulation in its life, would not recognise a tariff quota if one landed on its desk. Build our own classifiers, publish them, maybe collect 30 downloads of our own someday. One can dream.
Jupyter, but in the Cloud
Anyone who has written Python will have encountered Jupyter notebooks: the interactive coding environment where code lives in cells, runs one block at a time, and occasionally explodes because cell 7 was run before cell 3. Ever felt nostalgic for that experience? Google has you covered.
Google Colab is Jupyter in the cloud: same interface, same cell-based workflow, but hosted on Google’s infrastructure. The appeal is that Google will lend you a GPU to run your notebook on, free of charge. Since it is free, one does not exactly get cutting-edge technology. The GPU on offer is an Nvidia T4 with 15 GB of memory – hardware from 2018, which at the current pace of the industry might as well be a stone tablet. But it is enough for a 110-million-parameter model.
The other catch is that Google can revoke the GPU at any time, without warning, for any reason. Even if your model is mid-training and intermediate results have not been saved. Ask us how we know. (Actually, do not – we get to that shortly.)
One notebook, two models, one after the other. Both pointed at the 64,000 training regulations, three epochs each. Standard optimiser, standard loss function, nothing exotic. Click run. Wait.
The BERTs Go to Work
 Two and a half hours, zero euros, one regulation at a time. The glamour of machine learning.
Two and a half hours, zero euros, one regulation at a time. The glamour of machine learning.
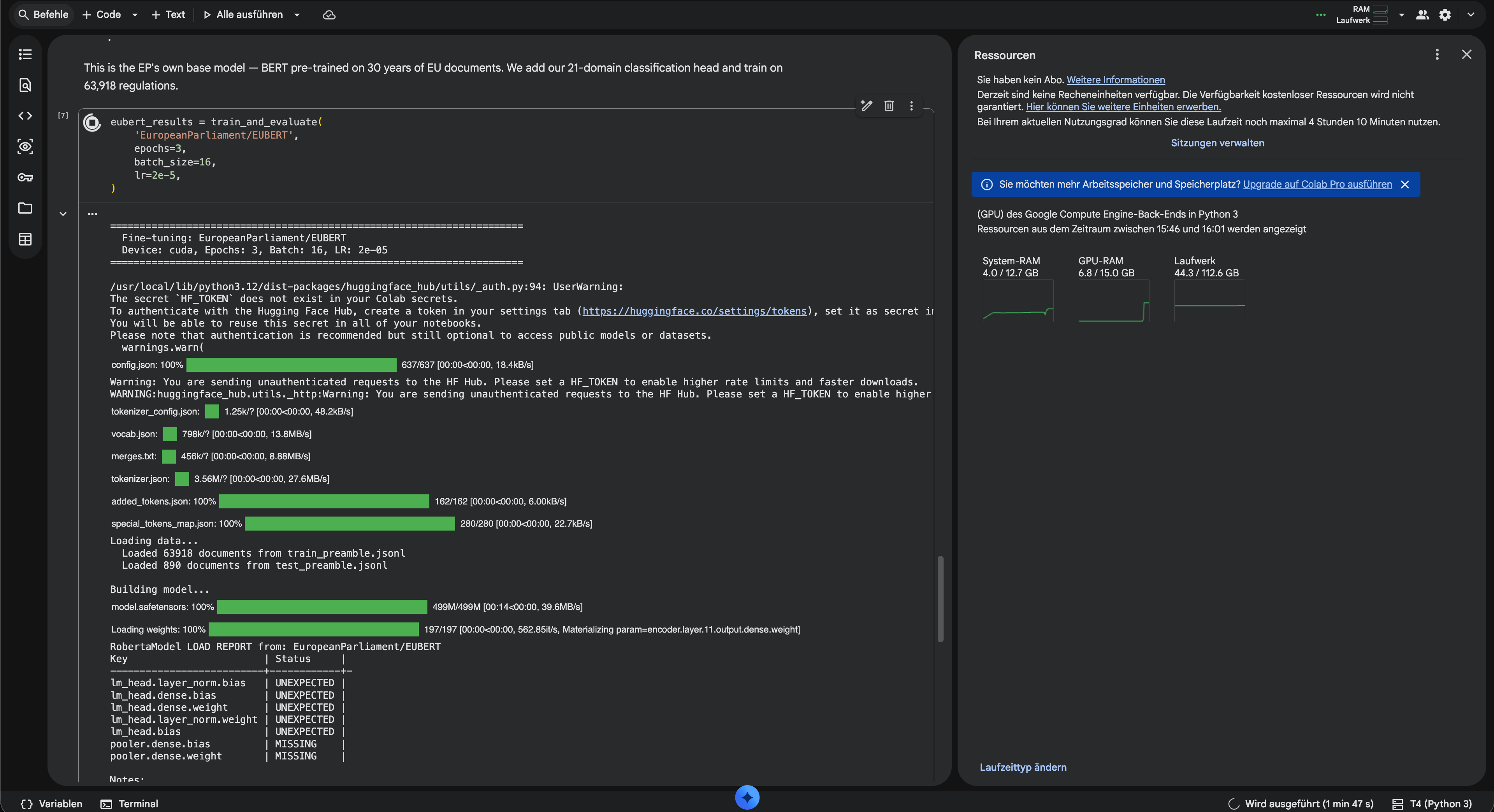
EUBERT went first. Within the first epoch, the intermediate metrics already looked promising – well above anything the zero-shot models had managed. The temptation was to stop early and celebrate, but the script had two more epochs to go and bert-base still queued behind it. Let it finish.
159 minutes later, EUBERT was done. No disconnections, no crashes, no drama. The script moved on to bert-base. First epoch completed smoothly. Halfway through the second – dead. No error, no warning, just a dropped connection and a notification that the free GPU allocation had been exhausted.
Free infrastructure works until it does not, and when it does not, you are on your own. Google giveth, Google taketh away. The free GPU was gone, the EUBERT results were saved, but bert-base had nothing to show for itself. The solution: €10 in paid compute units, the full script rerun from the top, and five hours later both models were done.
The results were worth the wait. EUBERT: 0.891. bert-base: 0.900. Both well above TF-IDF at 0.80, every zero-shot LLM a distant memory. And essentially identical to each other – the model trained from scratch on EU law and the one that had never seen a regulation in its life landed within a percentage point. With 64,000 examples to learn from, whatever the model knew beforehand simply did not matter.
Total bill for two fine-tuned classifiers that beat every method in the series: €10, with credits left. Combined training time: one afternoon.
Getting Ambitious
This would have been a reasonable place to stop. Two classifiers that actually work – which, given the European Parliament’s track record, is already an achievement worth noting. But 110 million parameters felt small. BERT is, by the standards of an industry that measures models in billions, a rounding error. What happens when you throw something bigger at the problem?
Enter: Llama 3.1 8B – Meta’s open-weight language model, eight billion parameters, seventy times the size of BERT. “Open-weight,” however, does not mean “help yourself.” Meta requires an access request, and the request was sent and access granted less than an hour later.
 Applied for the 8B, got the 70B on top apparently. We are not going to ask questions.
Applied for the 8B, got the 70B on top apparently. We are not going to ask questions.
Model downloaded, time to put it to work. A technique called QLoRA makes fine-tuning feasible by freezing the base model and training only a thin adapter on top. The downside: all eight billion parameters still pass through the GPU for every computation.
If two 110-million-parameter models already took five hours on the free GPU, eight billion were not going to fit on a T4 with 15 GB of memory – let alone finish in any timeframe compatible with human patience.
Time to switch to state-of-the-art machinery. Which comes at €2.73 per hour.
One might find it outrageous to pay that when Google hands out GPUs for free. But the free GPU is an Nvidia T4 from 2018 – far too slow and too small for this job. The H100 retails for around €30,000, and at €2.73 per hour it would take fifteen months of non-stop rental before buying one breaks even – before electricity, cooling, and maintenance enter the picture. So, basically a bargain.
If this were a sponsored blog, this would be the moment to welcome back our recurring sponsor. It is not sponsored, but we are happy to welcome back Scaleway – the European cloud provider whose GPU instances have featured in previous experiments, along with their invoices. (Again: not a sponsored arrangement, though at this point a volume discount would not go unappreciated.)
Pimp My Rig
The first attempt ran on a single H100 – one GPU, one machine, how hard can it be. At 1.3 documents per second, a single pass over 64,000 documents would take about 14 hours. Three epochs meant roughly 42 hours: two full days at €2.73 per hour, for a training run whose outcome was not guaranteed. BERT had finished in an afternoon for free.
Common logic suggests eight GPUs should deliver eight times the speed for more than eight times the price. In practice, the maths were kinder. As it happens, a language model is not the only thing you can pimp.
 “Yo dawg, I heard you like GPUs that don’t actually render graphics, so I put eight of them in a tray and connected them with a bus that’s faster than your internet.” – Jensen “The Jacket” Huang (presumably)
“Yo dawg, I heard you like GPUs that don’t actually render graphics, so I put eight of them in a tray and connected them with a bus that’s faster than your internet.” – Jensen “The Jacket” Huang (presumably)
The stock model – the one from the first attempt – used a standard PCIe slot. Same physical format as any desktop graphics card, slotted into a regular server. The entry-level ride. What Scaleway offered instead was the full upgrade: eight H100 SXM modules, each plugged into Nvidia’s proprietary socket and wired to the other seven via NVLink – Nvidia’s dedicated GPU-to-GPU interconnect running at 900 GB/s. That is fourteen times faster than the PCIe bus the stock card relied on. The SXM variant also reads its own memory 67% faster.
On a PCIe card, multi-GPU training is a conference call where everyone talks over each other. The SXM setup – proprietary socket, NVLink at 900 GB/s, 67% faster memory – turns it into a single conversation. Eight GPUs with 640 GB of memory between them, acting as one.
The code itself barely changed – HuggingFace’s Accelerate library handles the distribution automatically, splitting data across GPUs and synchronising gradients without touching the training logic.
One launch command, eight GPUs, 1.3 documents per second turned into 14.8 – not eight times faster, but 11.4 times. The estimated forty-two hours collapsed to three and a half. The run started at seven in the morning. By quarter to eleven, it was done.
The bill: €83. The F1 score: 0.892.
So this is what state-of-the-art architecture, eight of the most powerful GPUs on the market, and three and a half hours of training get you: a score that bert-base had already achieved for free. bert-base: 0.900. Llama: 0.892. Seventy times larger, eight times the hardware, more than eight times the price – and the needle barely moved.
The €83 did not buy accuracy. It bought speed.
So, Who Won?
| Method | Hardware | F1 (micro) | Time | Cost |
|---|---|---|---|---|
| bert-base (fine-tuned) | Nvidia T4 | 0.900 | 162 min | €10 |
| Llama 3.1 8B (QLoRA) | 8× Nvidia H100 | 0.892 | 3.6 h | €83 |
| EUBERT (fine-tuned) | Nvidia T4 | 0.891 | 159 min | free |
| TF-IDF + Logistic Regression | MacBook Air | 0.799 | 5 min | free |
| FastText | MacBook Air | 0.787 | 55 min | free |
| DeepSeek-R1-70B (zero-shot) | 8× Nvidia H100 | 0.562 | 31 min | ~€12 |
| SaulLM-141B (zero-shot) | 8× Nvidia H100 | 0.501 | 34 min | ~€12 |
| EuroLLM-22B (zero-shot) | 8× Nvidia H100 | 0.473 | 31 min | ~€12 |
Five articles and ten methods later, this is the full picture. Same 890 regulations, same human librarians as ground truth, same task – very different bills.
Read the table bottom to top and it tells you everything. The zero-shot models – the ones that were never shown what correct looks like – are at the bottom, struggling to clear 0.50 on a 21-label task. Above them, two classical methods that were actually trained: a word counter and FastText, both free, both around 0.80. And at the top, three fine-tuned models that cost between nothing and €83, clustered so tightly together that the difference barely registers.
The cheapest fine-tuned model scored the highest. The most expensive scored the lowest. Google’s 2018 BERT, trained on Wikipedia, beat Meta’s 2024 Llama, trained on everything. The difference: eight tenths of a percentage point and an order of magnitude in cost.
The jump from classical methods to fine-tuning was worth ten percentage points. The jump from €10 to €83 was worth minus one. The pattern is clear: the more you spend, the less the next euro buys you.
What This Suggests
Fine-tuning is where the real jump happens. A word counter on a laptop scored 0.80, a fine-tuned language model scored 0.90 – but an unfine-tuned one scored 0.50. That forty-point gap between guessing and learning is the single largest effect in the entire series. The difference is not the architecture. It is whether the model has seen what correct looks like.
More parameters do not mean better results. Llama is seventy times the size of BERT, capable of holding conversations and writing code – and it landed at essentially the same score, for more than eight times the price. When the task is sorting documents into drawers, the model needs to recognise patterns, and a small model does that just as well as a large one.
Throwing hardware at the problem makes it faster, not better. Eight GPUs delivered 11.4 times the speed of one – better than linear, thanks to NVLink – and compressed a two-day training run into a single morning. Magnificent engineering, but the final score did not care. The infrastructure turned days into hours without moving the needle by a single point. If time is the constraint, it is money well spent. If it is not, it is €83 worth of discovering that the ceiling can be reached for free.
So What?
Classification has a ceiling, and this series has hit it. A small model on a free GPU gets you there in an afternoon. A large model on expensive hardware arrives faster but at the same place, for an order of magnitude more money. The €83 did not buy a better classifier. It bought the certainty that scaling would not produce one.
Classification is solved. But summarising what a regulation actually says? That requires comprehension, not pattern matching – and comprehension is where the big models earn their keep. Assessing whether it conflicts with existing law? Harder still. The filing clerk handles the first job. The next ones need the kind of hardware this article just proved is overkill for sorting documents into drawers.
The skill is knowing which step you are on before reaching for the hardware.
Speaking of which: the European Parliament’s official classifier for EU regulations still does not work as advertised. In the spirit of transparency and for the benefit of all humanity, we built three that do and published them on HuggingFace under Apache 2.0, free to use.
Proudly published, occasionally downloaded, quietly ignored, and inevitably forgotten. But at least they load.
Licensed CC BY 4.0. Quote it, excerpt it, build on it – credit the author and link back.